- git clone下载项目
- 配置训练环境
- 下载通用模型,并解压粘贴至 PaddleOCR\
- 模型列表 models_list.md
- 用到的模型: ch_ppocr_server_v2.0_rec_pre-预训练模型
- 用到的配置文件: rec_chinese_common_train_v2.0.yml

- 数据集图片生成
- 这里采用TextRecognitionDataGenerator作为数据集图片的生成工具
- pip install trdg ↑
- trdg –output_dir “.\train\” –thread_count 16 –background 3 –image_dir “.\bg\” –font “.\pglh.ttf” –language cn –dict “.\word.txt” –word_split –text_color “#F3E6D6” -bl 1 –count 20000
- 字典word.txt请使用utf-8编码,以\r\n换行
| 参数 | 副参数 | 作用 |
| –output_dir | 生成图片输出路径 | |
| -i/–input_file | 生成图片中文字的源文件(路径),不指定用项目默认文件 | |
| -l/–language | 指定目标语言 | |
| -c/–count | 生成的图片数量 | |
| -rs/–random_sequences | -let/–include_letters -num/–include_numbers -sym/–include_symbols | 用字符随机生成单词,用于随机生成单词的字符中包含字母 用字符随机生成单词,用于随机生成单词的字符中包含数字 用字符随机生成单词,用于随机生成单词的字符中包含符号 |
| -w/–length | 随机生成图片包含的单词数 | |
| -r/–random | 以-w设置的单词数为上限,随机生成不同单词数的图片 | |
| -f/–format | 生成图片的像素高度(水平排版),生成图片的像素宽度(竖直排版) | |
| -e/–extension | 生成图片的保存格式,默认”jpg“ | |
| -t/–thread_count | 运行程序使用的线程数,实测8线程下,生成一万张图片仅需 6s,设置较高的线程可以明显提速 | |
| -k/–skew_angle | 文字在图片中的倾斜角度 | |
| -rk/–random_skew | 在倾斜角度 -k 设置的情况下,比如设为 a,则生成图片文字的倾斜角度在 -a~a之间随机选择 | |
| -wk/–use_wikipedia | 用维基百科作为单词源,生成图片,实测好像会连接失败 | |
| -bl/–blur | 设定图片的高斯模糊值,默认为0,即无高斯模糊处理,输入数据为int | |
| -rbl/–random_blur | 在设定高斯模糊值 -rbl 的情况下,比如设为b,则生成图片的高斯模糊值在 0~b之间随机取值 | |
| -b/–background | 设置图片的背景,0-高斯噪声; 1-白色背景; 2-quasicrystal; 3-自定义图片 | |
| -id/–image_dir | 在设定背景参数 -b 的值为3的情况下,从指定的图片文件夹中读取图片作为背景。 | |
| -hw/–handwritten | 利用训练好的RNN模型,生成手写字体图片(强大。。。) | |
| -na/–name_format | 生成图片的命名格式,图片名称通常包含标签,对于一些包含特殊符号的图片,由于图片命名中不能包含特殊图片,所以另生成一个文本记录标签。 | |
| -om/–output_mask | 对于每一张生成的图片,输出同样尺寸的掩码(全黑图片),训练的时候作为一种trick | |
| -d/–distorsion | 对生成图片中的文字进行扭曲,默认为0。1-正弦扭曲,2-余弦扭曲 | |
| -do/–distorsion_orientation | 在 -d 设定为正弦扭曲或者余弦扭曲的情况下,设定扭曲方向,0 – 竖直方向上的扭曲 1-横向扭曲 | |
| -wd/–width | 设定图片的像素宽度,在不指定的情况下,宽度为文本的宽度+10,假如设定宽度,过短会截取部分文本 | |
| -al/–alignment | 在设定文本宽度参数 -wd的情况下,截取文本的方式,0 -从左侧开始截取 1- 从中心向两边截取 2-从右侧开始截取 | |
| -or/–orientation | 文本在图片中的排版,0- 横向排版,1- 竖向排版,默认横向排版 | |
| -tc/–text_color | 文本的颜色,通过设定的颜色,或者颜色范围,生成特定颜色的文本,颜色格式为16进制 如:#282828,(#000000,#282828) | |
| -sw/–space_width | 设定图片中单词之间的像素间隔,默认为1像素 | |
| -cs/–character_spacing | 设定图片中字符之间的像素间隔,默认为0像素 | |
| -m/–margins | 设定图片中文本,上下左右的空白间隔,以间隔的像素值表示,默认(5,5,5,5,) | |
| -fi/–fit | 是否按文本裁切图片,使图片中文本上下左右的间隔均为0,默认为 False | |
| -ft/–font | 设定生成文本所用的字体文件(.ttf)格式 | |
| -fd/–font_dir | 设定生成文本所用字体的文件夹,生成的图片从文件夹中随机选择字体 | |
| -ca/–case | 设定图片中生成的文字大小写:upper/lower | |
| -dt/–dict | 设定从字典文件(路径)中选择单词生成图片 | |
| -ws/–word_split | 设定是设定根据单词还是字符分隔文字,True-根据单词 Talse-根据字符 | |
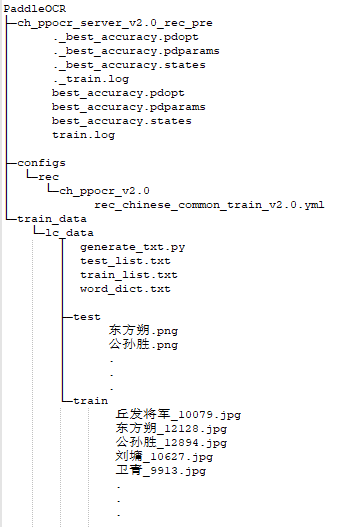
- 数据集目录xxxxx_data 用于保存训练需要的数据 PaddleOCR\train_data\xxxxx_data
- generate_txt.py 粘贴到 PaddleOCR\train_data\xxxxx_data\ 下,运行生成train_list、test_list、word_dict文件
# generate_txt.py
import os
# 生成字典
def word_dict():
rootdir = "./train/"
file_list = os.listdir(rootdir)
dict={}
for i in range(0, len(file_list)):
path = os.path.join(rootdir, file_list[i])
if os.path.isfile(path):
for s in os.path.basename(path).split(".")[0].split("_")[0]:
dict.update({s:0})
print(dict.__len__())
with open("./word_dict.txt", "w", encoding="utf-8") as file_object:
for s in list(dict):
print(s)
file_object.write(s+"\n")
# 生成测试图片列表
def generate_list(folder_name):
rootdir = "./"+folder_name+"/"
file_list = os.listdir(rootdir)
with open("./" + folder_name+"_list.txt", "w", encoding="utf-8") as file_object:
for i in range(0, len(file_list)):
path = os.path.join(rootdir, file_list[i])
if os.path.isfile(path):
str = folder_name + "/" + os.path.basename(path) + "\t" + os.path.basename(path).split(".")[0].split("_")[0] + "\n"
file_object.write(str)
print(str)
generate_list("test")
generate_list("train")
word_dict()
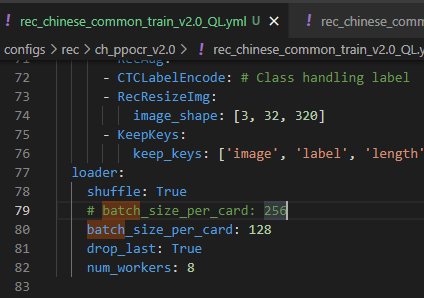
- 修改 PaddleOCR\configs\rec\rec_chinese_common_train_v2.0.yml
| 配置里对应的键 | 说明 | 是否必改项 | 值 |
| Global->pretrained_model | 预训练模型 | 必须 | ./ch_ppocr_server_v2.0_rec_pre/best_accuracy |
| Global->save_model_dir | 训练结果模型存放处 | 可选 | ./output/xxx_data |
| Global->character_dict_path | 使用的字典 | 必须 | ./train_data/xxx_data/word_dict.txt |
| Train->data_dir | 使用的训练图片目录 | 必须 | ./train_data/xxx_data |
| Train->label_file_list | 使用的训练图片统计列表文件 | 必须 | [“./train_data/xxx_data/train_list.txt”] |
| Eval->data_dir | 使用的测试识别图片目录 | 必须 | ./train_data/xxx_data |
| Eval->label_file_list | 使用的测试识别图片统计列表文件 | 必须 | [“./train_data/xxx_data/test_list.txt”] |
- 运行训练
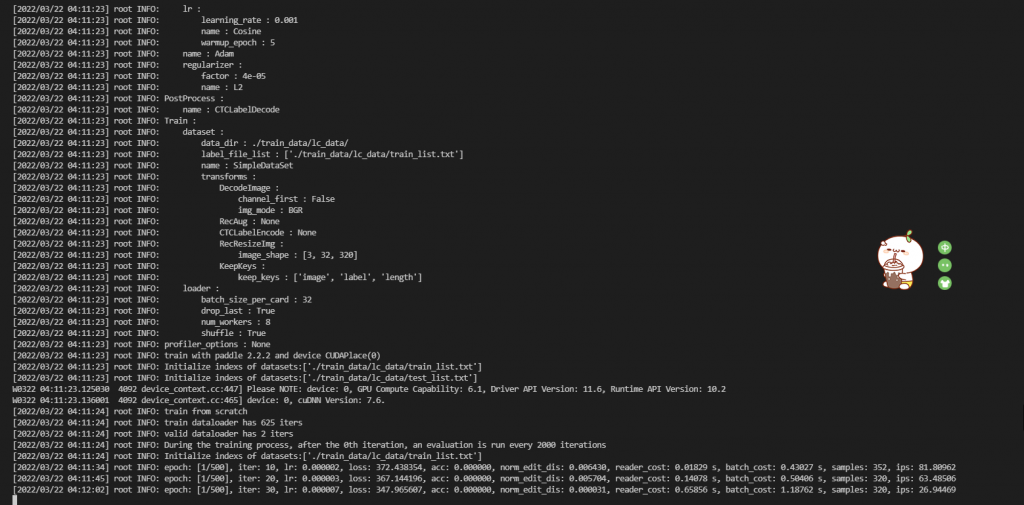
- python tools/train.py -c configs\rec\ch_ppocr_v2.0\rec_chinese_common_train_v2.0.yml

- 将训练结果转换为识别模型(可选)
- python tools/export_model.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_common_train_v2.0.yml -o Global.pretrained_model=./output/xxxxx_data/best_accuracy Global.save_inference_dir=./inference/xxxxx_data/
- 测试识别
- python tools/infer_rec.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_common_train_v2.0.yml -o Global.checkpoints=./output/xxxxx_data/best_accuracy -o Global.infer_img=”./xxxxx_data/test/”
问题汇总
- Out of memory error on GPU 0. Cannot allocate 640.000244MB memory on GPU 0, 3.707971GB memory has been allocated and available memory is only 298.912501MB.
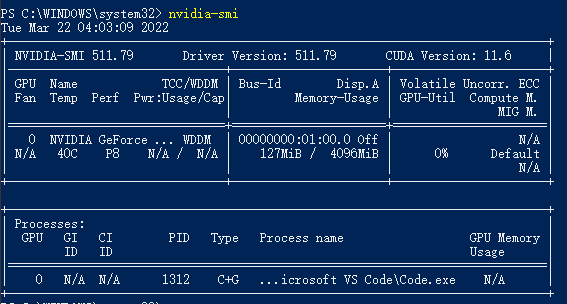
GPU0内存不足,解决方案
- 1.切到/添加其他GPU

#运行代码更改为
set CUDA_VISIBLE_DEVICES=0,1 ; python tools/train.py -c configs\rec\ch_ppocr_v2.0\rec_chinese_common_train_v2.0.yml- 2.减小batch size